| 1 | 80.5 | ||
| 2 | 79.0 | ||
| 3 | 78.4 | ||
| 4 | 76.6 | ||
| 5 | 74.3 | ||
| 6 | 73.8 |
About this benchmark
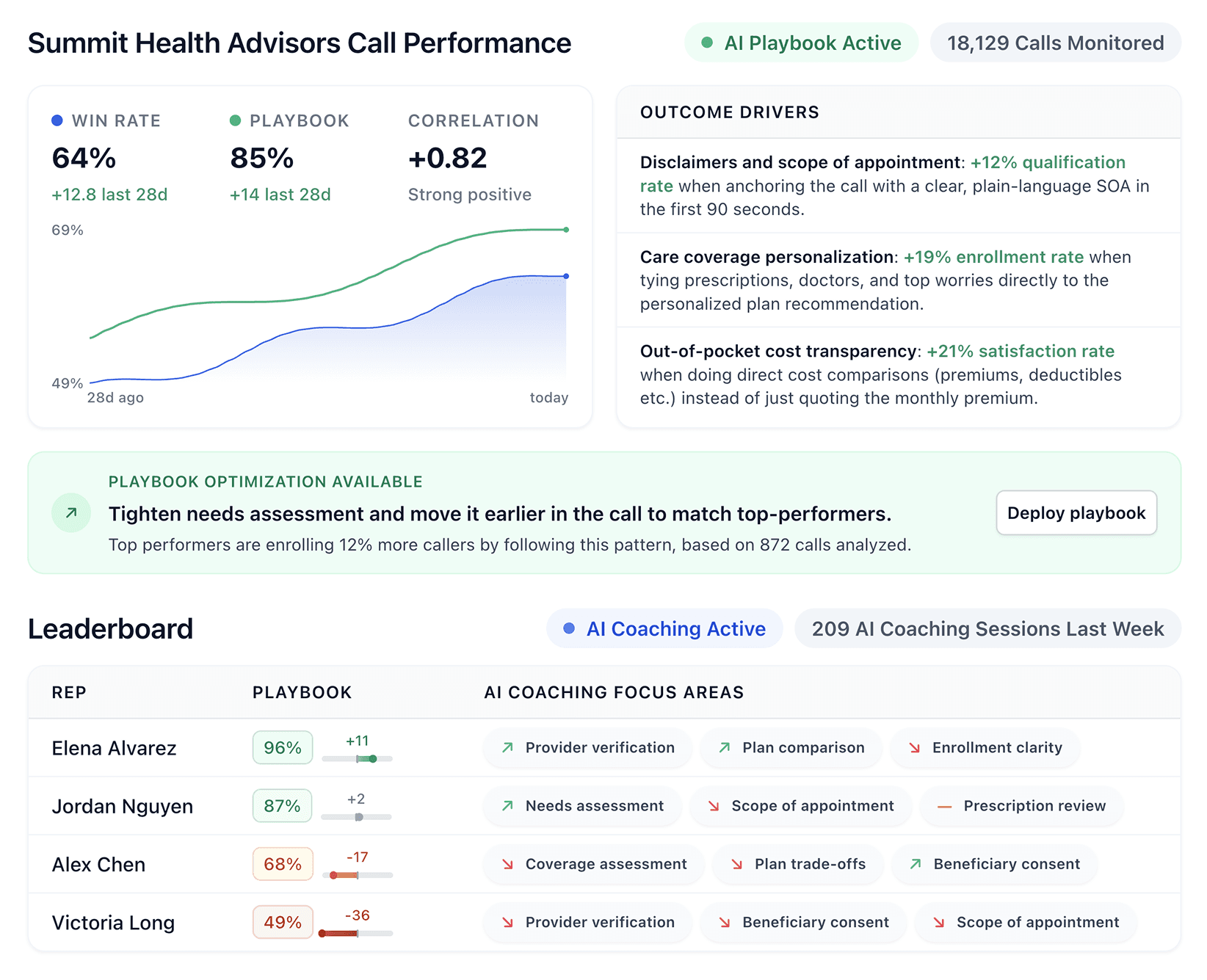
This benchmark measures how well AI models understand Medicare regulations, compliance requirements, and enrollment processes. Our test set covers general enrollment questions, plan comparisons, coverage inquiries, and compliance scenarios across varying complexity levels and thousands of real-world scenarios.
Each model is evaluated across three critical dimensions: CMS regulatory compliance, adherence to Medicare guidelines, and accurate plan information. These dimensions reflect the real-world requirements Medicare organizations face during audits and quality reviews.
Scores reflect how closely each model's assessments match those of certified Medicare specialists. Higher scores indicate more reliable and trustworthy Medicare knowledge.
We also factor in consistency—how reliably a model produces the same answer across multiple runs. A model that consistently gives the right answer is more valuable than one that randomly gets it right sometimes. Models with lower consistency receive a score penalty to reflect this unreliability.
| 1 | 97.8% | |
| 2 | 96.4% | |
| 3 | 95.0% | |
| 4 | 94.7% | |
| 5 | 92.5% | |
| 6 | 90.0% |
How accurate grading drives performance
Accurate grading models are the foundation of Alpharun's performance engine, which uses detailed transcript analysis to drive improved sales and compliance with personalized coaching. By pairing frontier models with bespoke AI playbooks, Alpharun provides fine-grained grading for every team member across dozens of criteria and thousands of monthly calls.
The following is an example of an Alpharun grade for a single criteria in a typical Medicare enrollment call:
Accurate, balanced explanation of options and trade-offs
Sharon Adams · September 3, 2025 at 8:15 PM PDT
Analysis
The advisor gives a neutral, side-by-side view of two viable paths and hits several core elements: premium and key copays:
He also addresses drug tiering basics and dental limits. However, he omits multiple material items: no mention of the plan's medical or Part D annual deductibles, does not state that PPOs generally require no referrals, and only briefly notes prior authorization for crowns whi...
By aggregating and analyzing hundreds of thousands of grading points, Alpharun then provides real-time coaching personalized to every rep, and optimized to focus on playbook elements that will maximize enrollment conversion and compliance.
AI coaching notes
Mon Sep 22 – Mon Sep 29
Compare specific drug costs across plans to make medication reviews tangible.
Great job turning medication lists into plan-specific guidance. With Sharon Adams , you made the review tangible by comparing Eliquis costs:"On the other MAPD with a $25 premium, Eliquis shows a $40 copay and fewer prior authorization flags. Your current PDP plan shows Eliquis with a $25 copay too."That kind of specificity builds confidence and aids decisions.
Use a 6-point checklist with specific dollar amounts for each plan comparison.
You're doing great with high-level contrasts, but clients need clear dollar amounts and benefit specifics. With David Clark , you stayed broad:"Right - Medicare Advantage plans (MAPD) bundle Part A, Part B and often Part D into one plan, sometimes with low or $0 premiums". To tighten up, use a 6-point checklist for each plan: premium (+"you still pay Part B") , medical deductible, PCP/specialist/ER copays, Inpatient costs, Part D deductible/tiers, and MOOP. Add network/referrals, and close with a quick teach-back.)
Performance vs cost
Cost per test reflects the relative pricing of running each model. The chart below reveals the value proposition of each solution, showing the balance of performance and affordability.
Beyond the limits of frontier models
While frontier models provide a strong foundation, Alpharun goes further by combining these capabilities with bespoke AI playbooks and knowledge bases tailored to each customer's unique requirements — compliance standards, sales methodologies, quality benchmarks and more.
Self-learning AI playbooks continuously improve by incorporating customer feedback and fine-tuning across hundreds of thousands of calls, ultimately producing grading accuracy, coaching quality, and performance transformation well beyond the limits of off-the-shelf models.
Methodology
Data collection
We curate a diverse dataset of Medicare scenarios covering enrollment questions, plan comparisons, coverage inquiries, and compliance situations—representing the full spectrum of challenges Medicare organizations encounter daily.
Expert review process
Each AI model receives identical test cases and standardized evaluation criteria. Models are assessed on compliance knowledge, regulatory understanding, and accuracy. Certified Medicare experts provide the ground truth used to calculate scores.
Fair comparison
To ensure fair comparison, all models are evaluated using equivalent prompt structures and default parameters. We deliberately include edge cases, ambiguous scenarios, and compliance-sensitive situations that stress-test each model's Medicare knowledge.